Matching with Jena
MELT contains built-in functionality to work smoothly with Apache Jena. You need to import the corresponding dependency for matcher development:
<dependency>
<groupId>de.uni-mannheim.informatik.dws.melt</groupId>
<artifactId>matching-jena</artifactId>
<version>2.6</version>
</dependency>
If you want to use matcher tooling (such as integrated usage of background knowledge, convenience functions, pre-built matchers), you need to import:
<dependency>
<groupId>de.uni-mannheim.informatik.dws.melt</groupId>
<artifactId>matching-jena-matchers</artifactId>
<version>2.6</version>
</dependency>
Check maven central for the latest version.
Developing Your Own Jena Matcher
If you develop a matching system based on Jena, you can extend the abstract class MatcherYAAAJena (rather than MatcherYAAA or IMatcher) and implement:
Alignment match(OntModel source, OntModel target, Alignment inputAlignment, Properties properties)
Chaining Jena Matchers
You can chain multiple Jena matchers using classes MatcherPipelineYAAA (Jena-independent) or MatcherPipelineYAAAJena (only Jena matchers).
Packaging Your First Jena Pipeline Matcher
The following example can be found in the examples directory (simpleMatcherPipelineYAAAJena). In the example, a new Matcher class MyPipelineMatcher is developed which extends MatcherPipelineYAAAJena. The initializeMatchers() method is implemented. In this method, two matchers are chained: ExactStringMatcher and a WordNet matcher. You can try out the new matcher by running the main method. Here, we run the matcher on the OAEI Anatomy test case.
If you remove a matcher component (method initializeMatchers()) and run the evaluation again, you will see that the performance changes. You can find a list of all matching systems and a list of all filters in the corresponding sections in the user guide.
// imports...
public class MyPipelineMatcher extends MatcherPipelineYAAAJena {
@Override
protected List<MatcherYAAAJena> initializeMatchers() {
List<MatcherYAAAJena> result = new ArrayList<>();
// let's add a simple exact string matcher
result.add(new ExactStringMatcher());
// let's add a background matcher
result.add(new BackgroundMatcher(new WordNetKnowledgeSource(),
ImplementedBackgroundMatchingStrategies.SYNONYMY, 0.5));
return result;
}
public static void main(String[] args) {
// let's initialize our matcher
MyPipelineMatcher myMatcher = new MyPipelineMatcher();
// let's execute our matcher on the OAEI Anatomy test case
ExecutionResultSet ers = Executor.run(TrackRepository.Anatomy.Default.getFirstTestCase(), myMatcher);
// let's evaluate our matcher (you can find the results in the `results` folder (will be created if it
// does not exist).
EvaluatorCSV evaluatorCSV = new EvaluatorCSV(ers);
evaluatorCSV.writeToDirectory();
}
}
Alternatively to extending class MatcherPipelineYAAAJena, you can use class MatcherPipelineYAAAJenaConstructor to pass the matching systems in the constructor.
Jena Helpers
LiteralExtractors
A recurring problem is obtaining natural language representations for Jena resources. LiteralExtractors address this problem by retrieving literals for any given Jena resource. Implementations include LiteralExtractorAllLiterals, LiteralExtractorByProperty, or LiteralExtractorUrlFragment. Refer to the JavaDoc documentation to find all implementing classes.
TextExtractors
TextExtractors work similar to LiteralExtractors but return strings (text) instead of Jena Literals. It is also possible to use a LiteralExtractor as a TextExtractor by wrapping it with TextExtractor.wrapLiteralExtractor(LiteralExtractor e).
In addition to the already discussed LiteralExtractors, some special predefined TextExtractors are:
-
TextExtractorSetwhich returns the highest amount of literals because it retrieves all literals where the URI fragement of the property is eitherlabel,name,comment,description, orabstract. This includes also the propertiesrdfs:labelandrdfs:comment(because the URI fragment islabelrespecitvelycomment). Furthermore, the propertiesskos:prefLabel,skos:altLabel, andskod:hiddenLabelfrom theskosvocabulary are included as well as the longest literal (based on the lexical representation of it). Additionally, all properties which are defined asowl:AnnotationPropertyare followed in a recursive manner in case the object is not a label but a resource. In such a case, all annotation properties of this resource are added. The extractor reduces the potentially large set of literals by comparing the normalized texts and only returns the ones which are not identical (note here that the original literals are returned, not the normalized ones). -
The
TextExtractorShortAndLongTextsreduces the set of literals byTextExtractorSetfurther by checking if a normalized literal is fully contained in another literal. In this case, the literal is also not returned. This is only applied within the two groups of long and short texts to extract not only a long abstract but also a short label. The long texts are classified by the property that is used. Label-like properties are regarded as short texts and comment/description properties are regarded as long texts. -
TextExtractorForTransformersextracts the smallest number of literals (out of the three text extractors presented here) by returning exclusively labels that are not contained in other labels (without distinguishing in long and short texts). This results in reducing the set of strings even more because labels which appear in a comment are also not returned.
Following a small example: 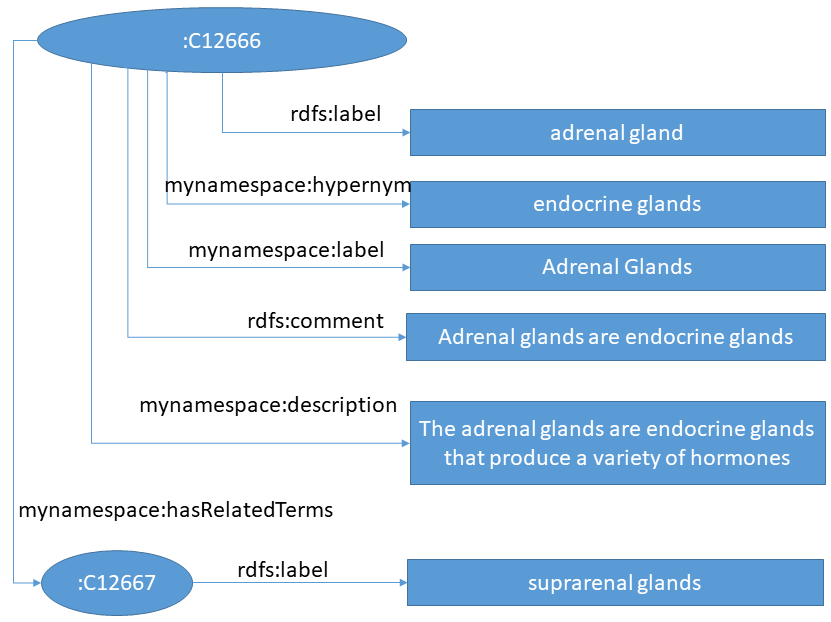
In this example the TextExtractorSet extracts all literals except endocrine glands because the property hypernym is not used. Also note that mynamespace:hasRelatedTermsis of type owl:AnnotationProperty because otherwise suprarenal glands would be also not extracted. Due to the fact that normalization does not remove plural s both literals of rdfs:label and mynamespace:label are returned. The latter is chosen because the fragment of the property URL is called label. Thus the resulting literals are: adrenal gland, Adrenal Glands, Adrenal glands are endocrine glands, The adrenal glands are endocrine glands that produce a variety of hormones, and suprarenal glands
The TextExtractorShortAndLongTexts reduce this to only three returned literal because adrenal gland is contained in Adrenal Glands and the normalized text of rdfs:comment is contained in the normalized text of mynamespace:description. Thus the following literals are returned: Adrenal Glands, The adrenal glands are endocrine glands that produce a variety of hormones, and suprarenal glands
The TextExtractorForTransformers reduces this further because the restriction that short and long texts are handled separately is now cancelled. And because Adrenal Glands appears in mynamespace:description it is also not returned. Thus the final extracte literals are: The adrenal glands are endocrine glands that produce a variety of hormones and suprarenal glands
Those TextExtractors are often used in matching components where a textual description of a resource is necessary. This is the case for e.g. transformer-based components like TransformersFilter.
For testing the extractors on real world data, you can use class ManualInspection which is contained in the test scope of the jena-matchers project. A usage example of of this class can be found in ManualInspectionMain.