Matching with Multiple Sources
The main interfaces for multi source matching are located in the matching base project. It contains the extended matcher interface IMatcherMultiSource which is different from the normal matcher interface because it expects not only two ontologies/KGs but a list of them. The aforementioned interface is generic in the way that the implementer can choose which java representation (class) is used for ontologies and alignments.
Implementations which reuses a 1:1 matching system
The following figure shows an example of four KGs A, B, C, and D, which are matched with different multi-source approaches.
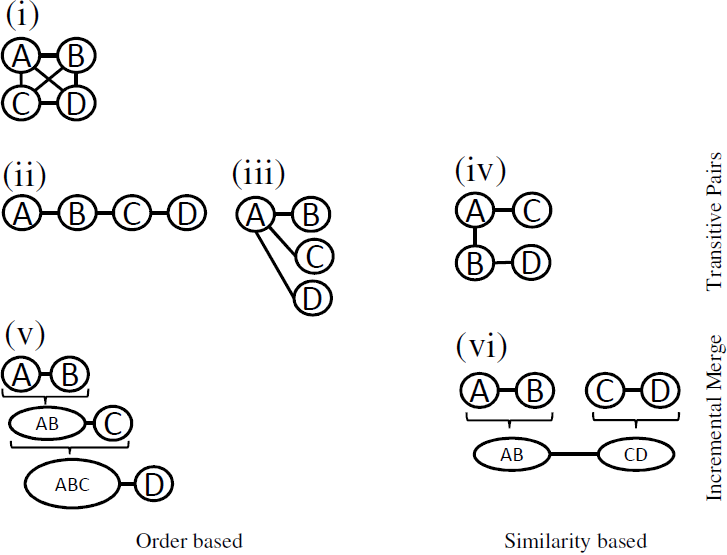
Each of them will be shortly presented. All implementations are located in the matching-jena-matchers project.
(i) All Pairs
In this approach, all possible combinations of the KGs are matched. Therefore, it is a combination without repetition taken two KGs at a time.
Implementation: MultiSourceDispatcherAllPairs
(ii) Transitive Pairs: Windowing
The goal of this approach is to reduce the number of matching executions while keeping at least a (transitive) connection between all sources. It should be clear that these approaches reduce the number of executions with the drawback that not all matches might be found. E.g. if there is a concept in source A named Ai and corresponding match in source C named Ci, then it is possible to find the correspondence <Ai, Ci> only in the case where source B also contains a resource Bi which should be matched both Ai and Ci. Creating the execution plan for this approach requires an order of the KGs. All order are defined as Comparator<? super ModelAndIndex>. Some example implementations are available as static members of class MultiSourceDispatcherIncrementalMergeByOrder. Here the windowing approach is followed, which means that the first KG (in the example it is A) is matched to the second KG (B) and then the second KG to the third one and so on (window size of two).
Implementation: MultiSourceDispatcherTransitivePairsOrderBased and setting firstVsRest in the constructor to false.
(iii) Transitive Pairs: First vs Rest
This approach is similar to the previous one but it will not match the first one (e.g. the one with the highest or lowest number of classes)with the second one in the list. Instead the first KG is chosen as a hub and all other KGs are matched to it.
Implementation: MultiSourceDispatcherTransitivePairsOrderBased and setting firstVsRest in the constructor to true.
(iv) Transitive Pairs: Similarity
Approaches (ii) and (iii) need an ordering to obtain the final execution plan. It is also clear that if a concept is not appearing in all KGs, that ordering can lead to missed correspondences. The main idea of similarity based approaches is to find KGs with a similar topic and to match them first. Therefore, a minimum spanning tree of these sources are computed with Kruskal’s algorithm. Computing such a tree always requires weighted edges which should represent in this case the topical closeness of KGs. The weighting is computed by the cosine similarity of tf-idf vectors to mitigate the impact of terms which often appears (such as upper level ontology terms). Those vectors are generated by iterating over all literals in the KG which contains text and all URI fragments (part after the last slash / or hashtag #). Literal texts are processed by sentence splitting, tokenization, lowercasing, stopword removal, and stemming. The fragments are tokenized additionally with camel case and some common separators such as minus (-), underscore (_), and tilde (~). The sentence splitting is left out for the fragments because it usually does not form a whole sentence.
Computing the final execution plan works as follows:
- For each source KG, the tf-idf vector based on the texts in the KG is computed
- The cosine similarity for each possible matching pair is calculated
- The distances are sorted in ascending order
- Each pair is added as long as there is no cycle / the source and target KG does not belong to the same transitive closure.
Implementation: MultiSourceDispatcherTransitivePairsTextBased
(v) Incremental Merge: Order Based
Incremental Merge based approaches, in contrast to the transitive pairs ones, do not leave the input knowledge graphs untouched, but merge two KGs after matching them. All available orderings from (ii) can be reused.
One important step is to create the union of the two KGs given the alignment between them. All subjects, predicates, and objects of each triple are checked and resources (represented by a URI) are replaced with the URI of the target concept. If no information of already matched entities should be included in the union, you can set addInformationToUnion to false in the constructor of MultiSourceDispatcherIncrementalMerge or any subclass.
After one merge is finished, the result is used directly in the next run of the binary matcher. Thus, systems which are aware of being used in such a scenario, can reuse a potentially build index for the next run. For such a warm start, all triples which are added to the union, are also fed into the matching system for updating necessary indices (i.e., it does not reload the knowledge graphs from scratch in the next run). If the matcher has no warm start feature, in each run a larger KG needs to be read.
Implementation: MultiSourceDispatcherIncrementalMergeByOrder
(vi) Incremental Merge: Similarity
Similar to the approach (iv), the incremental merge strategy cannot only be used with the order based approach but also with the textual similarity of KGs. The idea is again to first match sources which share the same topic and then all others. The actual execution plan is calculated by a hierarchical agglomerative clustering. The result is a hierarchy of clusters which can directly be used as an execution plan. In the beginning, each KG is its own cluster and the algorithm searches for the next best KG to form a new cluster. The similarity between clusters can be determined with single, average or complete link strategies. The clustering input is the tf-idf vector of each KG which is described in (iv). In comparison to the order based incremental search, it is now possible that two already merged KGs should be matched together. In such a case the larger union in terms of statements is selected as the target except that one of them is the result of a previous matching operation. The reason is that the matcher with the warm start feature needs to only update its index with the given subset of triples.
Implementation: MultiSourceDispatcherTransitivePairsTextBased
Other approaches
There are more approaches on how to reduce the multi-source KG matching task to multiple binary matching problems. An example of such an approach would be to create the union of all KGs and match the union to itself (implementation: MultiSourceDispatcherUnionToUnion) Such approaches are not used often because they will not respect the goal of a 1:1 matching system to provide at most one corresponding concept for a given resource.