Matching with Machine Learning | General Information
Python Integration
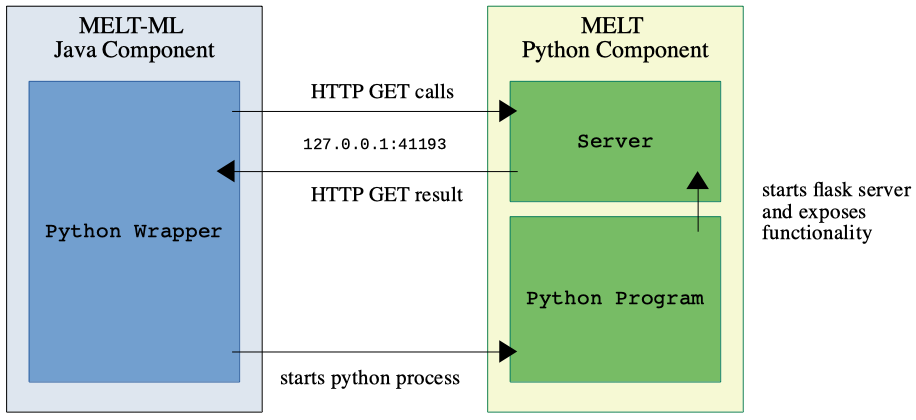
The MELT-ML module exposes some machine learning functionality that is implemented in Python. This is achieved through the start of a python process within Java. The communication is performed through local HTTP calls. This is also shown in the following figure.
The program will use the default python command of your system path. Note that Python 3 is required together with the dependencies listed in /matching-ml/melt-resources/requirements.txt.
If you want to use a special python environment, you can create a file named python_command.txt in your melt-resources directory (create if not existing) containing the path to your python executable. You can, for example, use the executable of a certain Anaconda environment.
Example:
C:\Users\myUser\Anaconda3\envs\matching\python.exe
Here, an Anaconda environment, named matching will be used.
Obtaining Training Data
Machine learning requires data for training. For positive examples, a share from the reference can be sampled (e.g. using method generateTrackWithSampledReferenceAlignment) or a high-precision matcher can be used. Multiple strategies exist to generate negative samples:
For example, negatives can be generated randomly using a absolute number of negatives to be generated (class AddNegativesRandomlyAbsolute) or a relative share of negatives (class AddNegativesRandomlyShare). If the gold standard is not known, is also possible to exploit the one-to-one assumption and add random correspondences involving elements that already appear in the positive set of correspondences (class AddNegativesRandomlyOneOneAssumption). MELT contains multiple out-of-the box strategies that are already implemented as matching components which can be used within a matching pipeline. All of them implement interface AddNegatives. Since multiple flavors can be thought of (e.g. generating type homogeneous or type heterogeneous correspondences), a negatives generator can be easily written from scratch or customized for specific purposes. MELT offers some helper classes to do so such as RandomSampleOntModel which can be used to sample elements from ontologies.
Matching with Transformer Models
Using a Transformer as Filter
MELT offers the usage of transformer models through a filter class TransformersFilter. For reasons of performance, it is sensible to use a high-recall matcher first and use the transformer components for the final selection of correspondences. Any transformer model that is locally available or available via the huggingface repository can be used in MELT.
In a first step, the filter will write a (temporary) CSV file to disk with the string representations of each correspondence. The desired string representations can be defined with a TextExtractor. The transformer python code is called via the python server (see above).
The TransformerFilter is intended to be used in a matching pipeline:

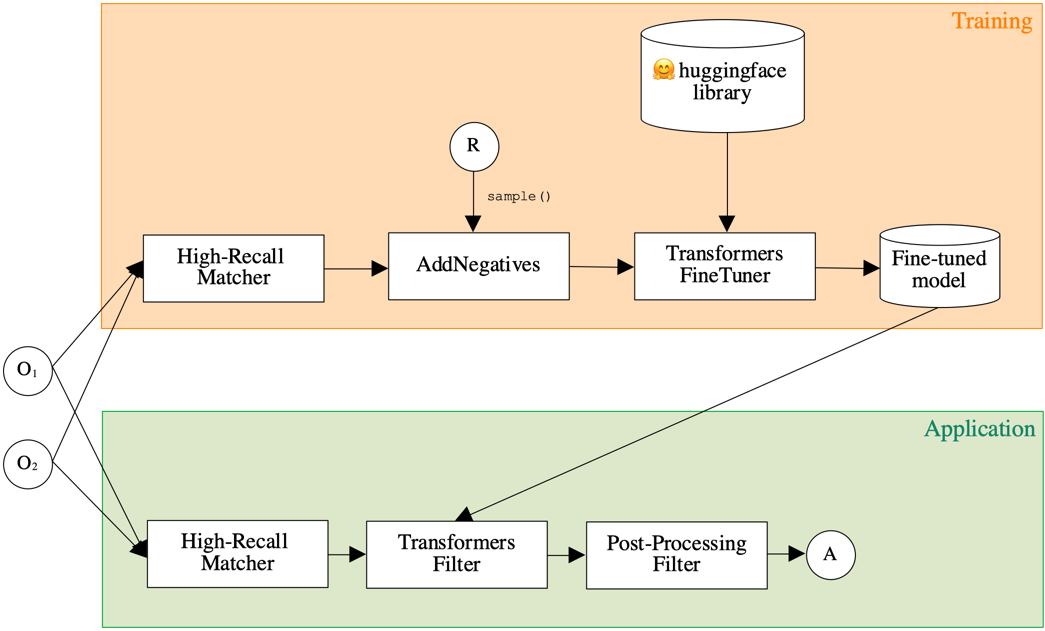
Fine-Tuning a Transformer
The default transformer training objectives are not suitable for the task of ontology matching. Therefore, a pre-trained model needs to be fine-tuned. Once a training alignment is available, class TransformersFineTuner can be used to train and persist a model (which then can be applied in a matching pipeline using TransformerFilter as shown in the figure above).
Like the TransformersFilter, the TransformersFineTuner is a matching component that can be used in a matching pipeline. Note that this pipeline can only be used for training and model serialization. An example for such a pipeline is visualized below: